
Supervised vs. Unsupervised learning
Machine learning algorithms are described as either 'supervised' or 'unsupervised'. The distinction is drawn from how the learner classifies data. In supervised algorithms, the classes are predetermined. These classes can be conceived of as a finite set, previously arrived at by a human. In practice, a certain segment of data will be labelled with these classifications. The machine learner's task is to search for patterns and construct mathematical models. These models then are evaluated on the basis of their predictive capacity in relation to measures of variance in the data itself. Many of the methods referenced in the documentation (decision tree induction, naive Bayes, etc) are examples of supervised learning techniques.Unsupervised learners are not provided with classifications. In fact, the basic task of unsupervised learning is to develop classification labels automatically. Unsupervised algorithms seek out similarity between pieces of data in order to determine whether they can be characterized as forming a group. These groups are termed clusters, and there are a whole family of clustering machine learning techniques.
In unsupervised classification, often known as 'cluster analysis' the machine is not told how the texts are grouped. Its task is to arrive at some grouping of the data. In a very common of cluster analysis (K-means), the machine is told in advance how many clusters it should form -- a potentially difficult and arbitrary decision to make.
It is apparent from this minimal account that the machine has much less to go on in unsupervised classification. It has to start somewhere, and its algorithms try in iterative ways to reach a stable configuration that makes sense. The results vary widely and may be completely off if the first steps are wrong. On the other hand, cluster analysis has a much greater potential for surprising you. And it has considerable corroborative power if its internal comparisons of low-level linguistic phenomena lead to groupings that make sense at a higher interpretative level or that you had suspected but deliberately withheld from the machine. Thus cluster analysis is a very promising tool for the exploration of relationships among many texts.
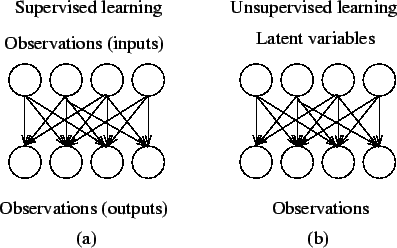
Figure 2 illustrates the difference in the causal structure of supervised and unsupervised learning. It is also possible to have a mixture of the two, where both input observations and latent variables are assumed to have caused the output observations.
With unsupervised learning it is possible to learn larger and more complex models than with supervised learning. This is because in supervised learning one is trying to find the connection between two sets of observations. The difficulty of the learning task increases exponentially in the number of steps between the two sets and that is why supervised learning cannot, in practice, learn models with deep hierarchies.
In unsupervised learning, the learning can proceed hierarchically from the observations into ever more abstract levels of representation. Each additional hierarchy needs to learn only one step and therefore the learning time increases (approximately) linearly in the number of levels in the model hierarchy.
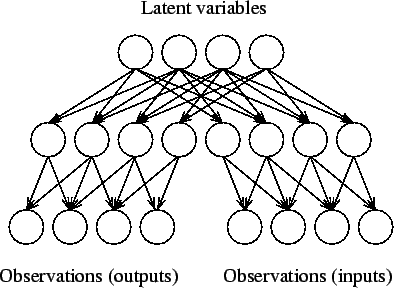
If the causal relation between the input and output observations is complex -- in a sense there is a large causal gap -- it is often easier to bridge the gap using unsupervised learning instead of supervised learning. This is depicted in figure 3. Instead of finding the causal pathway from inputs to outputs, one starts building the model upwards from both sets of observations in the hope that in higher levels of abstraction the gap is easier to bridge. Notice also that the input and output observations are in symmetrical positions in the model.
 |
No comments:
Post a Comment